Introduction#
Heterogeneous Entries in Parallel File (hepfile)#
High energy physics (HEP) experiments involve colliding subatomic particles at close to the speed of light, and looking at the particles produced by these collisions. Each collision (or event, in HEP parlance), can produce a different number of of particles, thanks to the probabilistic nature of quantum mechanics. One collision could produce 3 muons, 2 electrons, 9 pions, and 12 photons, and the next colliions could produce 7 muons, 0 electrons, 22 pions, and 33 photons. These datasets require file formats that can accomodate this type of numerical heterogeneity, since we can’t easily break this down into a simple n x m array. Simply put, HEP datasets don’t lend themselves to .csv files or spreadsheet analysis.
This challenge was solved more than 20 years ago with the widespread adoption of the ROOT file format, a format tied to the ROOT analaysis toolkit at CERN. However, the monolithic and HEP-specific nature of ROOT has made it challenging at times to share data with the broader computing community. We believe that HDF5, a portable and commonly used file format outside of HEP, holds promise in being a useful file format for many HEP analysts.
One issue is that HDF5 works best with homogenous data formats, where each dataset occupies an n x m chunk of memory. To work with
WE PROVIDE DICTIONARY TO WORK WITH TO DEAL WITH SUBSETS OF THE DATA.
METADATA AND HEADER.
Schema#
Heterogenous Data…#
We assume that data that we collect is composed of (insert some term for particle, chair, etc.) each carrying a certain number of attributes. Each ___ is associated with some increasing counter. In HEP, this counter is events. Each event can have an arbitrary number of particles of any type, making this data heterogenous.
…to Homogenous File#
To make this data homogenous, we can create n by m chunks of data for each type of particle, where n is the total number of this particle in all of the events, and the specific row for each of the particles contains all of the attributes for that particle in the original data.
We also create a list for each type of particle whose length is the total number of events. At position i, we have the data for how many particles of said type appeared in event i.
Overview of use case#
hepfile is useful for datasets where there are n columns with different numbers
of rows. In more “pythonic” language, you can imagine a dictionary where each key
has a different number of values. For example:
data = {x: [1],
y: [1, 2],
z: ['1', '2', '3']
}
This can not simply be converted to most common data structures, like a Pandas DataFrame, or written to a simple homogeneous file structure, like a CSV file. In a more complex case Let’s have an image of a town, with cartoon people here.
To illustrate how to use hepfile with this example, we imagine a researcher conducting a census on a town. Each household in the town has some variable number of people in it, some variable number of vehicles, and only one residence. The people, vehicles, and residence all have different data associated with them. How would we record these data? Well, to first order, we might decide to record them in multiple spreadsheets or multiple .csv files.
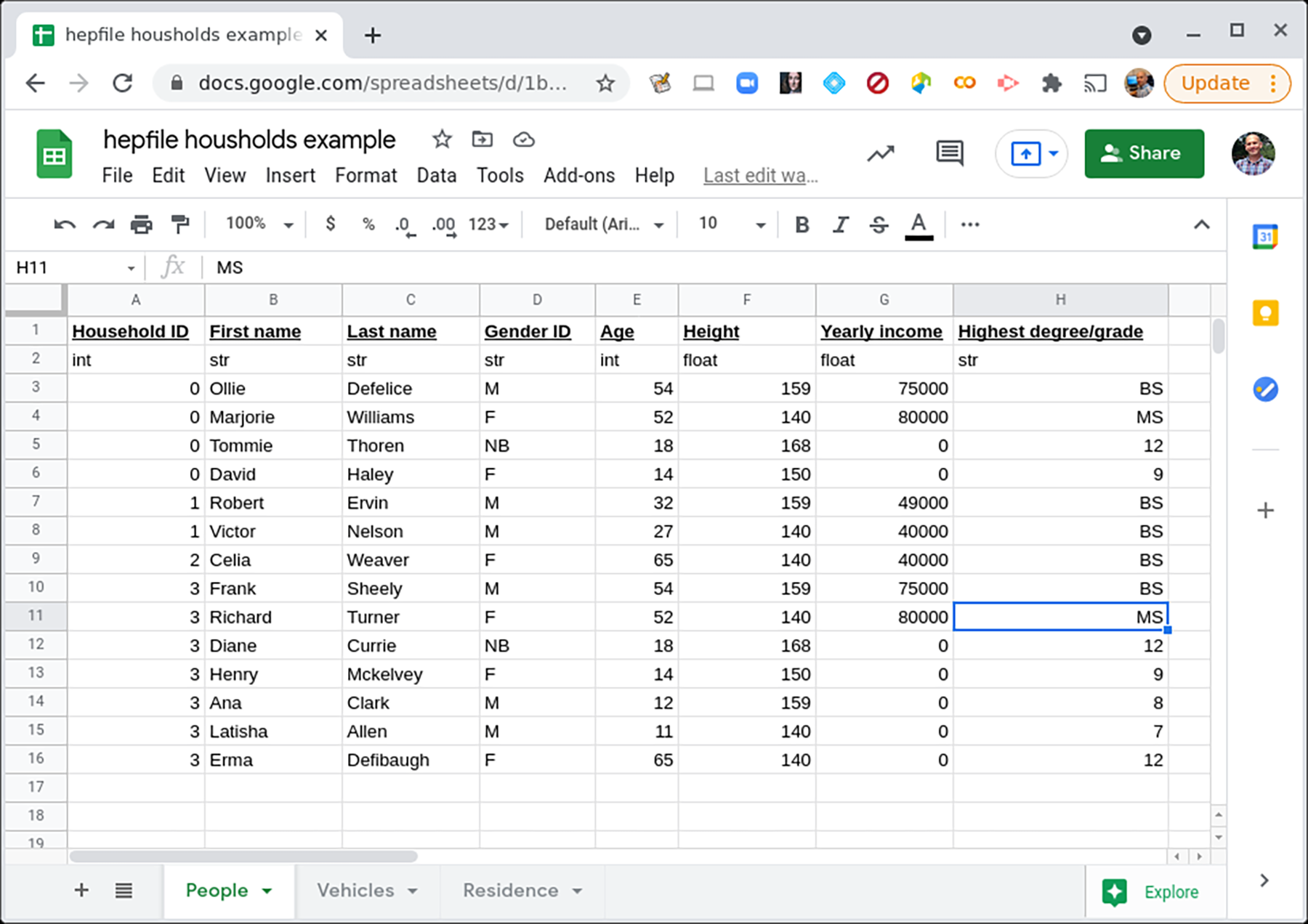
Click on the image to see a fuller view of the data on the People.#
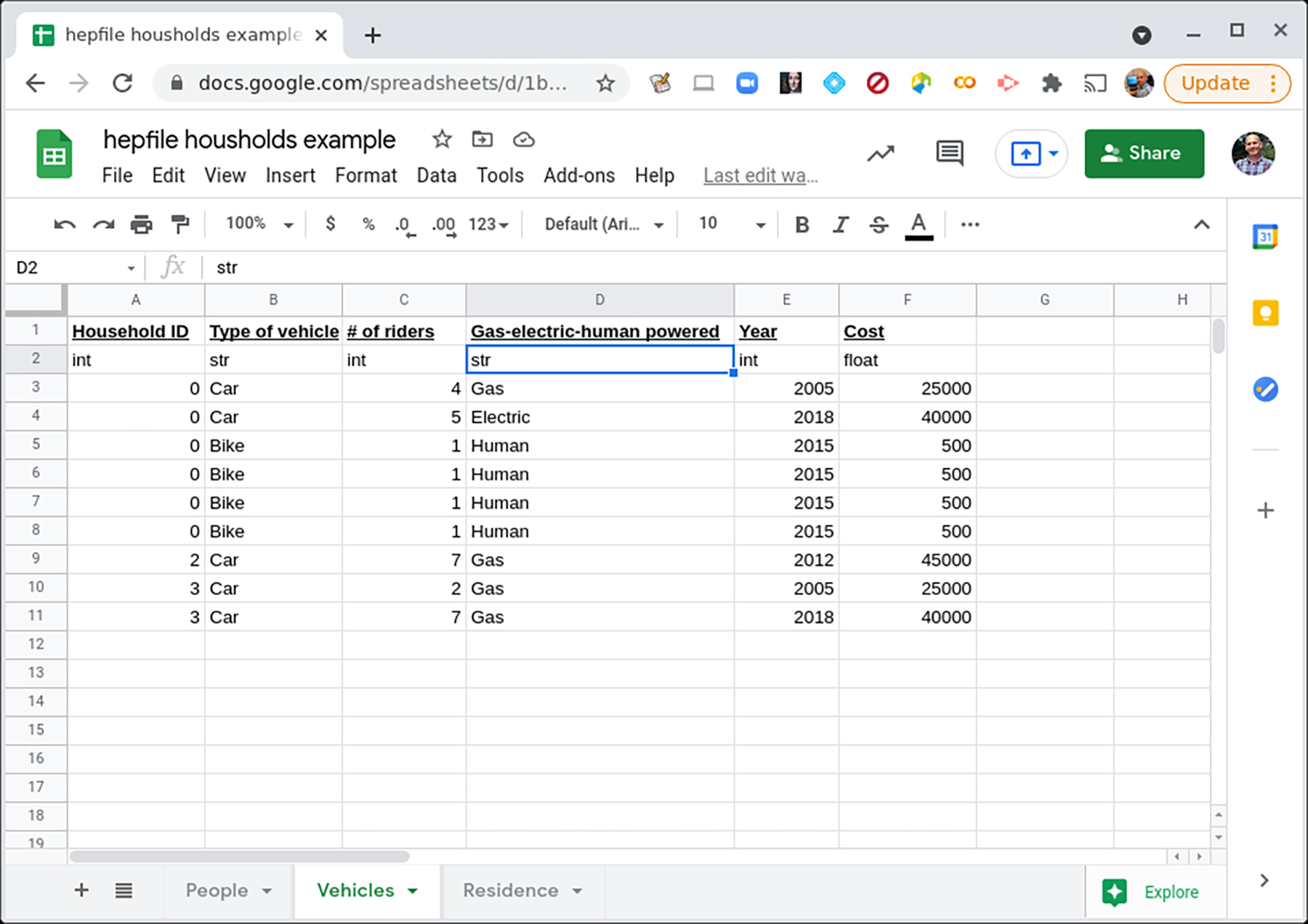
Click on the image to see a fuller view of the data on the Vehicles.#
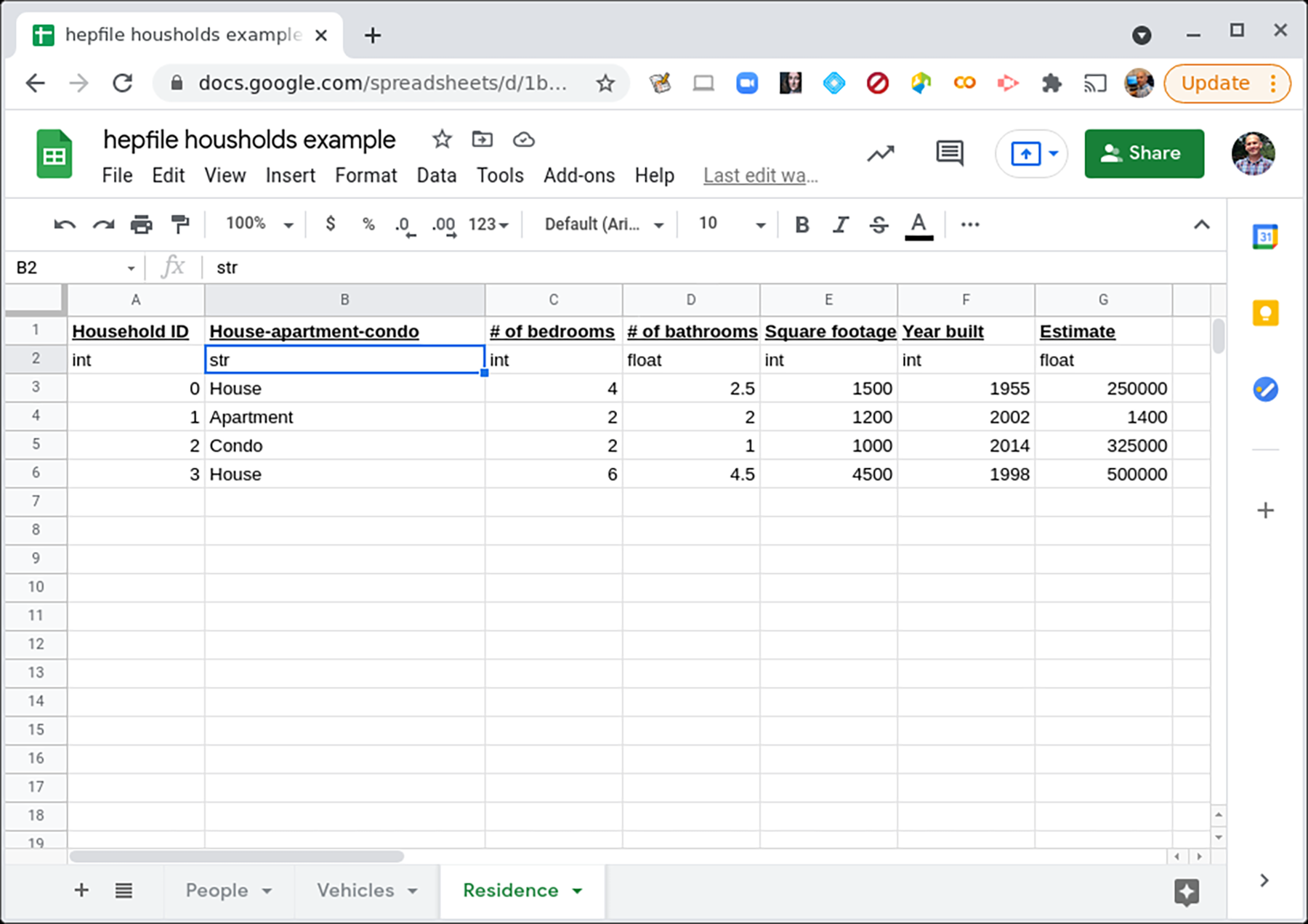
Click on the image to see a fuller view of the data on the Residences.#
One could also imagine this data stored in a database with each of the csv files as tables. But the goal is to keep all of this data in one file, so that it is easier for someone to do analysis. For example, someone might want to know the average number of people per bedroom, in the homes. Or the average number of vehicles as a function of combined ages of the household residents. If we have 3 separate files, this is more difficult to work with. What we want is one file and a way to extract information, collected by household.
To do this, we need some way to count the number of people or vehicles in any household, as well as keep track of what data fields will always have one entry per household (e.g. data about the residence itself).
One could imagine building a very large `pandas <https://pandas.pydata.org/>`_ dataframe to do this
with a lot of join statements and then use .groupby() approach or to store this in a database and
then use a lot of SQL join statements. But we want to store this in a single file so. instead, we will
take our cue from ROOT and particle physicists, who are used to looping over subsets of their data.
Installation quickstart#
User Installation#
For non-developers, hepfile can be installed using pip.
hepfile includes some optional features that include optional dependencies so there are multiple
different options for installation.
The base package gives you the ability to read and write hepfiles using the more standard “loop & pack”
method and the dictionary tools. This is the “lightest” of the installation options and is only dependent
on numpy and h5py. To install the base package use:
python -m pip install hepfile
You can also get the awkward_tools which is the hepfile integration with the awkward package. This is
especially recommended for High Energy Physicists who are used to working with awkward arrays. The only
dependency this add is awkward. To install this version of the package use:
python -m pip install hepfile[awkward]
You can get the more data science focused tools by installing the df_tools and csv_tools. These provide
integration with pandas and typical csv files. This is recommended for those who are used to working
with pandas in python. This adds a a pandas dependency to the base installation. To install this distribution use:
python -m pip install hepfile[pandas]
To get both the awkward and pandas integration with hepfile (which adds pandas and awkward to the base installation dependencies) use:
python -m pip install hepfile[all]
Finally, for those running the example notebooks locally,
you should install with the learn optional dependency because some of the tutorials rely on dependencies
like matplotlib and astropy:
python -m pip install hepfile[learn]
Developer Installation#
For a local installations, typically for developers, follow these steps:
Clone this repo
Navigate to the top-level directory of this project (probably called hepfile)
We then recommend installing with the developer dependencies. To do this run:
python -m pip install -e '.[dev]'
Then, run the following commands to setup the pre-commit git hook to automatically run our tests before committing!
pre-commit install
As a side note, to test developments to this code use the following command in the top-level directory of this project:
pytest